
必要な競馬データを収集したら、次は集計と分析です。

集計軸は非常に多く、シンプルな人気や過去走の着順平均などでは一定の傾向は示せるものの、精度の高い予測は出来ません。ここのブログでは最終的に機械学習を使って精度の高い予測を目標としています。
コースデータについて
コースデータとは、ここでは以下の組み合わせを差します
- 競馬場
- 芝/ダート
- 距離
これらを軸に集計を行います。
いきなり個別のレースを予測するのではなくコースごとの傾向を掴むことから始めましょう。
コースデータを軸に、以下の情報たちを掛け合わせて集計していきます
- 馬場状態
- 天気
- グレード
- 枠番・馬番
- 人気・単勝オッズ
- 重量(斤量)
- 上がり3F・前半3F
- 初角通過順位・最終コーナー通過順位
一色単に書いてしまいましたが、コースごとにタイムを集計し、その後、コースごとに、例えば、枠番によるタイムや着順を比較していきます。
そうすることでコースによって有利な枠番や位置取りがわかるかもしれません。
コース集計・分析
取得済みのレース一覧と結果一覧データを結合して取り込んだデータをall_dfとしています。
この大本のデータに関しては今回は略です。いろいろ加工はしています。
以下の処理でグレードと馬場でタイム関連のデータに対して各集計を取ります。
そして基準点がほしいので(後々にコースの違いを吸収するため)、基準コースを選択して各コースを計算します。
### コース×グレード×馬場のタイム
course_grade_baba_g_df = all_df.groupby(course_h+["grade","馬場"]).agg({
"RID": ["count","nunique"],
"タイム2": ["min", lambda x: x.quantile(0.25), "mean", "median", lambda x: x.quantile(0.75), "max", "var"],
"前半3F": ["min", lambda x: x.quantile(0.25), "mean", "median", lambda x: x.quantile(0.75), "max", "var"],
"上り3F": ["min", lambda x: x.quantile(0.25), "mean", "median", lambda x: x.quantile(0.75), "max", "var"],
"道中タイム": ["min", lambda x: x.quantile(0.25), "mean", "median", lambda x: x.quantile(0.75), "max", "var"]
}).reset_index()
course_grade_baba_g_df.columns = [c[0] + c[1].replace('<lambda_0>', '四分位一位').replace('<lambda_1>', '四分位三位') for c in course_grade_baba_g_df.columns]
# 基準は東京 芝 2000 未勝利 良 1403
diff_target_columns = course_grade_baba_g_df.iloc[:, 7:].columns
insert_col_name = ["東京芝2000未勝利良比較"+c for c in diff_target_columns]
standard_values = course_grade_baba_g_df.loc[1403][diff_target_columns]
course_grade_baba_g_df[insert_col_name] = course_grade_baba_g_df[diff_target_columns] / standard_values
結果の一部が以下
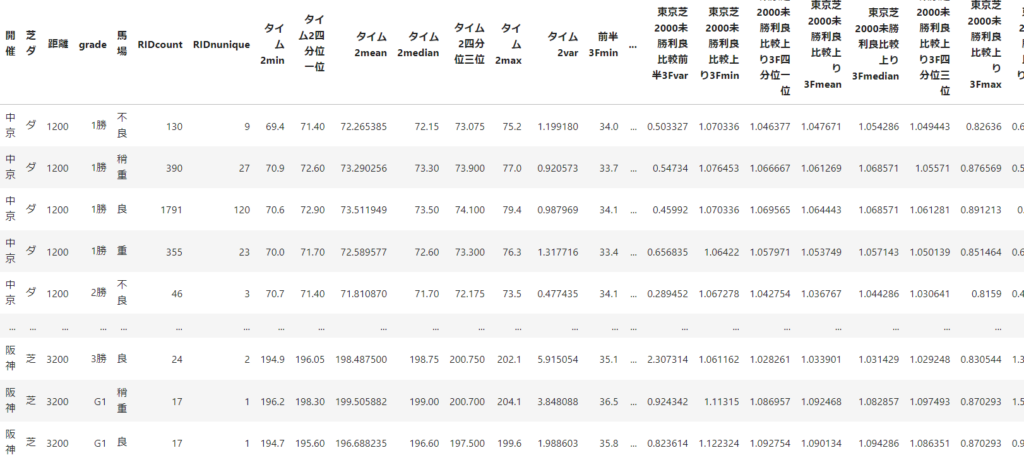
今後、このデータを使用してグレード間やコース間の違いをコンバートして比較に使っていきます。

