
私はフリーランスでメインはデータを扱う仕事をしています。
その他ですとjavascript/react/typescriptを使用したフロントエンドの作成・バックエンドAPIの作成やAWSを使用したインフラの整備や動画編集・ウェブサイトの運用をしています。
一番長くやっているのがpythonとデータベースを連携したデータ取得・加工・集計・分析・運用といったデータのライフサイクルを扱う仕事で
趣味で競馬分析を行っていることから、特に、このココナラやその他クラウドソーシングでは競馬のデータ取得や分析などのツール作成を請け負うことが多いです。
そこで今回は競馬データを扱うことをテーマにブログを書いていこうと思います。
第一弾はnetkeibaからレースデータを取得する方法をして紹介します。ややプログラムを書く技術者よりになると思いますが、手っ取り早くデータ取得ツールが必要な方はツールを作成して出品しておきますので、ご購入のご検討をお願いします。
第1回 競馬レース一覧を取得するツールを提供します レース一覧を自動スクレイピングで取得しようまたpythonを扱う方はコピペでデータ取得できるように書いていきます。
※また自分が超めんどくさがりなので詳細な説明は省き、結論のコードだけのせることも多いと思います。
- 第1回はnetkeibaからレース日程とレース一覧を取得する方法
- 第2回はnetkeibaから出走表とレース結果とその他結果データ(払い戻し等)を取得する方法
- 第3回はnetkeibaから競走馬のプロフィール・過去レース結果を取得する方法
を予定しています。
第4回以降は未定で、その他のデータ取得方法/データベース格納/統計学と集計方法/競馬×機械学習入門、このあたりを書こうかと考えています。
前置きはこのくらいにして、早速データ取得に移りましょう。
まずは前提や準備として
詳しくは説明しませんが、サーバに負荷をかける行為は妨害とみなされるのでやめましょう。
ここでは
使用ブラウザ:googleCrome
使用言語:python
使用外部ライブラリ: selenium, webdriver_manager, pandasを使用します。
プログラムからブラウザを立ち上げる
pythonプログラム(selenium)はブラウザを操作するためにブラウザのドライバーが必要になります。
ご使用中のバージョンに合わせてダウンロードし、seleniumにドライバーのPathを教えるという方法がオーソドックスでしょうが、
ブラウザのバージョンが変わるに連れてドライバをダウンロードして再設定するのは面倒です。そのためにwebdriver_managerというライブラリを使用します。
以下がブラウザを立ち上げるコードです。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
def get_driver(opt=1):
options = Options()
if opt is None:
options.add_argument('--headless')
return webdriver.Chrome(ChromeDriverManager().install(), options=options)
### ※最新のseleniumではwebdriver_manager不要でwebdriver.Chrome()だけで処理ができるみたいです。
driver = get_driver() # 実行そうすると空のブラウザが立ち上がります。
アクセスとレース日程
次にnetkeibaにアクセスします。
url = "https://www.netkeiba.com"
driver.get(url) # getでURLのページを開く
まずレース日程のページを開いてURLを確認すると
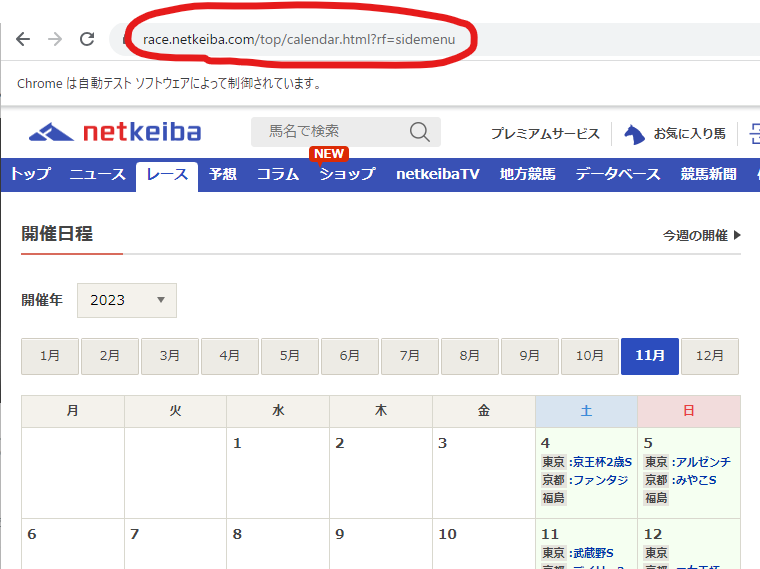
このURLでは11月しか取得できませんね。
試しに10月のタグをクリックすると
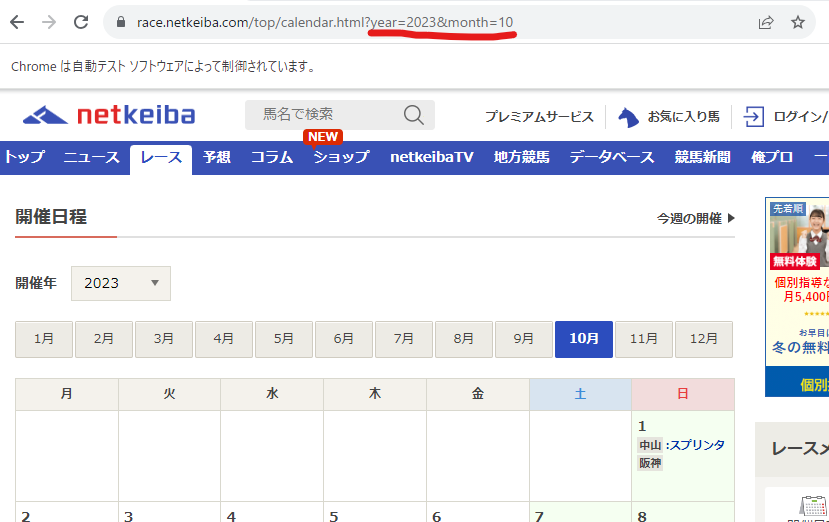
以下のようにURLが変わりました。
calendar.html?year=2023&month=10
試しにmonth=11にブラウザ上のURLを変えると、最初のURLと同様になります。
つまり、このyearとmonthのパラメータを変えればまずは各年月のページは取得できそうです。
ざっとページを見渡すと開催日には、開催場所とメインレースのリンクが貼ってあるので、それを利用して開催日を取得します。
ブラウザ上でF12キーを押して開発者ツールを開きます。
開発者ツールの左上の矢印アイコンをクリックしてからカーソルをウェブページの任意の箇所に当てると、その箇所のHTMLが取得できます。そして構造を解析していきます。
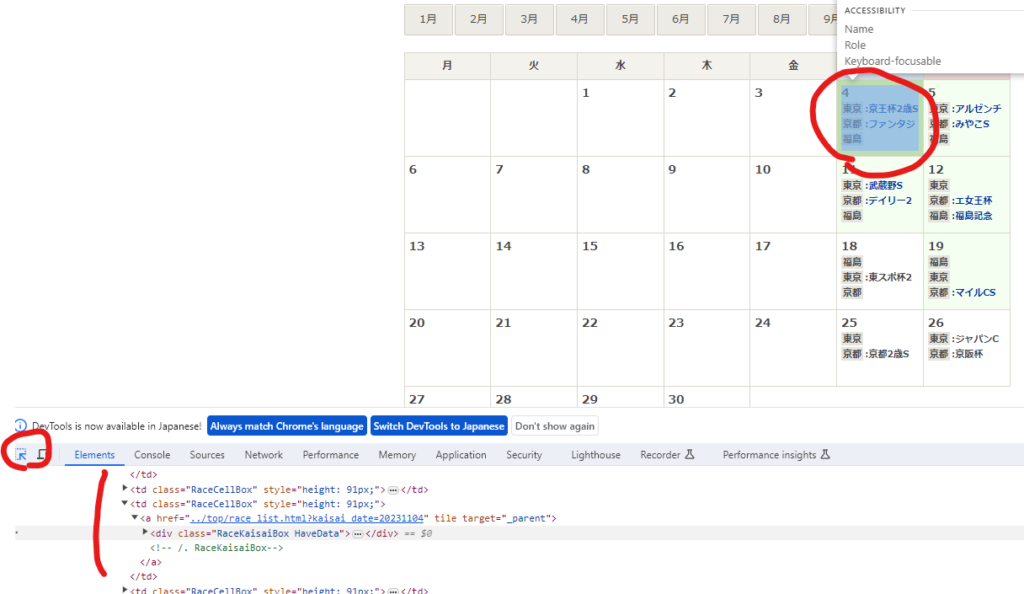
いろいろな解析方法がありますが、私はカレンダー内の各セルのclass名がRaceCellBoxであることに注目します。そしてdriver.find_elements関数ですべてのRaceCellBoxエレメントを取得して、そこに<a>タグがあるかどうかで開催日かどうかを判定します。以下が開催日一覧を取得する関数です。
from time import sleep
from urllib import parse
from selenium.webdriver.common.by import By
def parse_url(url, search_s):
parsed_url = parse.urlparse(url)
params = parse.parse_qs(parsed_url.query)
target = params.get(search_s, [None])[0]
return target
def get_kaisai_date(driver, year, month):
url = f"/calendar.html?year={year}&month={month}" # 禁止ワードらしいのでネットケイバのURLを入れてください
driver.get(url)
sleep(2)
CalendarSelectMenu = driver.find_element(by=By.CLASS_NAME, value="CalendarSelectMenu")
Race_Calendar_Main = CalendarSelectMenu.find_element(by=By.CLASS_NAME, value="Race_Calendar_Main")
RaceCellBoxes = Race_Calendar_Main.find_elements(by=By.CLASS_NAME, value="RaceCellBox")
ancs = []
for RaceCellBox in RaceCellBoxes:
_a = RaceCellBox.find_elements(by=By.TAG_NAME, value="a")
if len(_a) == 1:
ancs.append(_a[0].get_attribute("href"))
kaisai_dates = [parse_url(anc, "kaisai_date") for anc in ancs]
return kaisai_datesこれは引数にdriver, year, monthを与えるとその年月の開催日を取得する関数です。
parse_url関数は<a>タグ内にリンク先の日付が入っていることに着目した関数です。
以下のように実行します。例えば2022年6月の開催日一覧が欲しい場合
response = get_kaisai_date(driver, "2022", "06")
# responseは以下のようになりました
['20220604', '20220605', '20220611', '20220612',
'20220618', '20220619', '20220625', '20220626']
実際のページを見ても正しそうです。

以下のように引数の年と月をループさせれば簡単に指定の年月のレース開催日を取得できます。
years = ["2021", "2022"]
monthes = [str(m) for m in range(1, 13)]
kaisai_dates = []
for year in years:
for month in monthes:
kaisai_dates += get_kaisai_date(driver, year, month)
print(kaisai_dates)特定日付のレース一覧
さて、開催日がわかったところで、次は特定の日付のレース一覧を見ていきます。
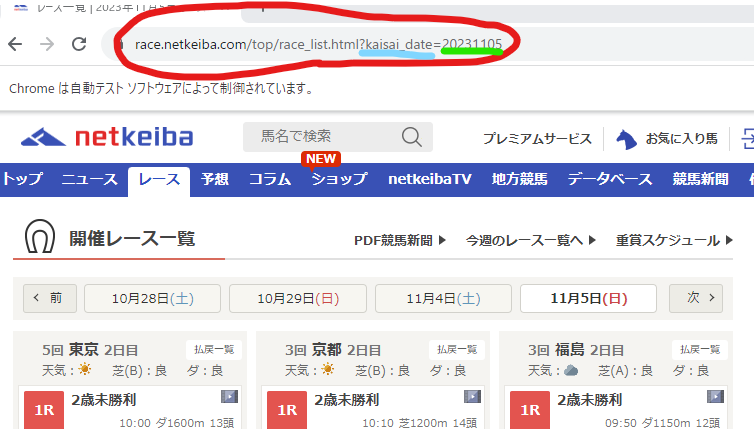
URLをみるとkaisai_dateパラメータにYYYYMMDDの形式で年月日を入れるとレースページが取得できることがわかります。
試しにブラウザ上のURLの日付をいじってみてください。該当の日付のレース一覧ページに飛び、開催が存在しない日程であれば、ローディングアニメーションが表示されます。
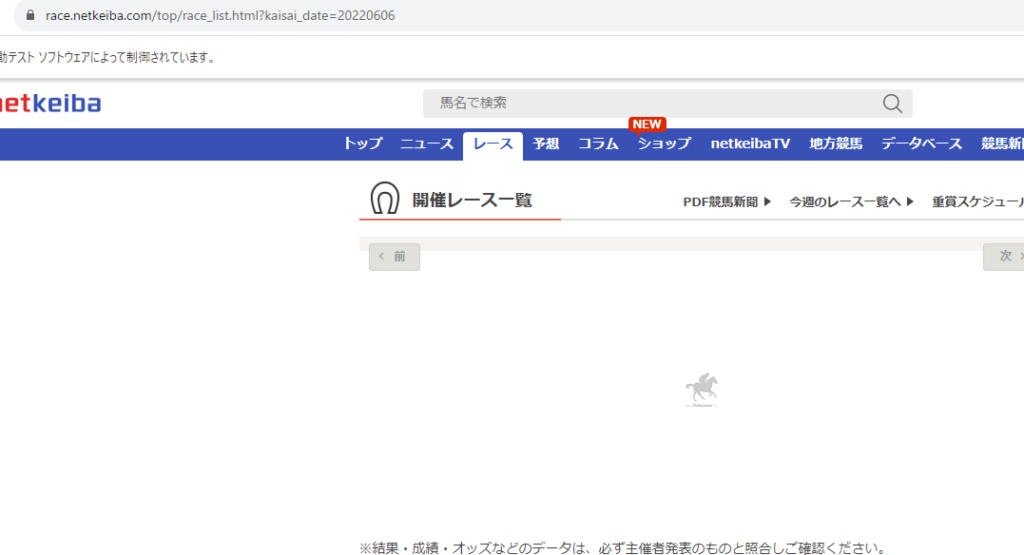
では20220605のレース一覧を取得します。
同様に開発者ツールを開き、HTML解析を行うと
今回もclass名に着目し、開催場所毎に”RaceList_DataList”というクラスで設定されていることがわかります。
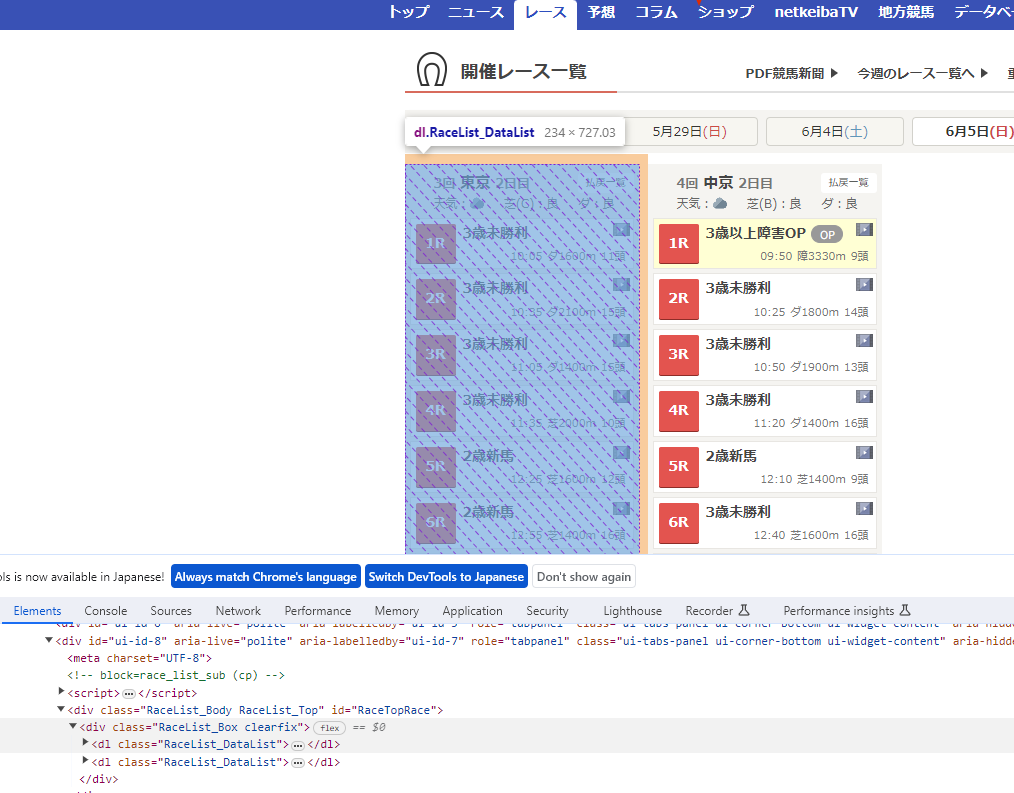
その後もclass名に着目し、
各レースリストをループし、レース名や芝ダや距離などの情報を取得していきます。
長くてややこしいので詳細な説明は略。以下取得関数です
from time import sleep
import pandas as pd
from selenium.webdriver.common.by import By
def get_race_list(driver, select_datetime):
url = f'/top/race_list.html?kaisai_date={select_datetime}' # 禁止ワードらしいのでホームページを追加してください
driver.get(url)
sleep(3)
# sleep(3)
rs = driver.find_elements(by=By.CLASS_NAME, value='RaceList_DataList')
rsnames = [rsn.find_element(by=By.CLASS_NAME, value='RaceList_DataTitle').text for rsn in rs ]
racelist = []
for rss in rs:
rsname = rss.find_element(by=By.CLASS_NAME, value='RaceList_DataTitle').text
rsis = rss.find_elements(by=By.CLASS_NAME, value='RaceList_DataItem')
for rsi in rsis:
rsia = rsi.find_element(by=By.TAG_NAME, value='a')
rsin = rsi.find_element(by=By.CLASS_NAME, value='Race_Num')
rsi2 = rsi.find_element(by=By.CLASS_NAME, value='RaceList_ItemContent')
rsi2t = rsi2.find_element(by=By.CLASS_NAME, value='ItemTitle')
rsi2gradebk = rsi2.find_elements(by=By.CLASS_NAME, value='Icon_GradeType')
if len(rsi2gradebk) > 0 and 'Icon_GradeType ' in rsi2gradebk[0].get_attribute('class'):
classes = rsi2gradebk[0].get_attribute('class').split(" ")
rsi2grade = class_grade_mapper[classes[1]]
else:
rsi2grade = "未勝利"
rsi2d = rsi2.find_element(by=By.CLASS_NAME, value='RaceData')
rsi2d2 = rsi2d.find_element(by=By.CLASS_NAME, value='RaceList_Itemtime')
rsi2d3 = rsi2d.find_elements(by=By.CLASS_NAME, value='RaceList_ItemLong')
if rsi2d3 is not None and rsi2d3 != []:
rsi2d3 = rsi2d3[0].text
else:
rsi2d3 = rsi2d.find_elements(by=By.TAG_NAME, value='span')[1].text
rurl = rsia.get_attribute('href')
rid = select_rid(rurl)
racelist.append((rsname,rsin.text,rsi2t.text,rsi2d2.text,rsi2d3,rurl,rid,rsi2grade))
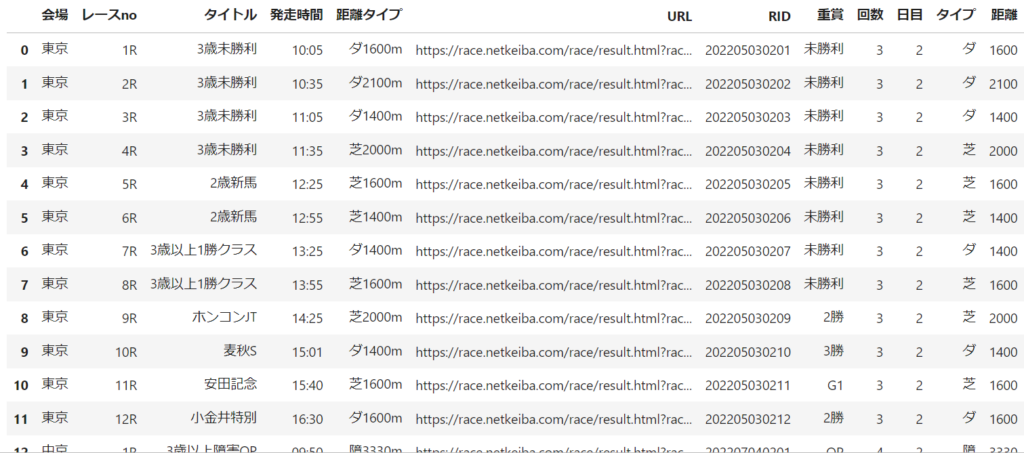
racelistpd = pd.DataFrame(racelist,columns=['会場','レースno','タイトル','発走時間','距離タイプ','URL','RID','重賞'])
racelistpd['回数'] = racelistpd['会場'].str[0]
racelistpd['日目'] = racelistpd['会場'].str[6]
racelistpd['会場'] = racelistpd['会場'].str[3:5]
racelistpd['タイプ'] = racelistpd['距離タイプ'].str[0]
racelistpd['距離'] = racelistpd['距離タイプ'].str[1:5]
return racelistpdこの関数はレース一覧をpandasDataframeにして作成します。
データフレームはエクセルみたいにデータ保持ができると思ってください。
以下のように実行します
race_list = get_race_list(driver, "20220605") # 20220605のレース一覧を取得すると以下のように結果が返ってきます。
終わりに
いかがだったでしょうか。競馬好きでpythonが扱える方は試してみてください。
また今回のレース日程からレース一覧を取得してエクセルで出力するツールをtkinterで作成してますのでプログラムが苦手な方は覗いてみてください。
次回は出走表・結果・払い戻し一覧を取得する記事とツールの作成をする予定です。

