
netkeibaからデータを取得するの第二弾です。

前回は指定の日付範囲から日程とレース一覧を取得しましたが、
今回は具体的な出走表と結果と払い戻しを取得します。
netkeibaには通常の結果とデータベースの結果ページが存在しますが、今回は前者をターゲットとします。
対象ページの確認
まずは出走表のページを見ると、
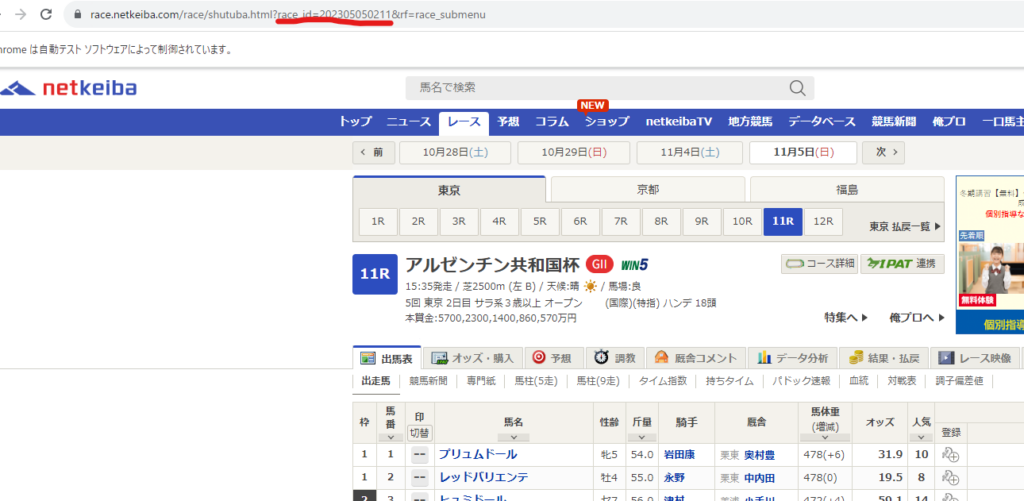
レースIDが書いてます。そして結果ページも同様です。
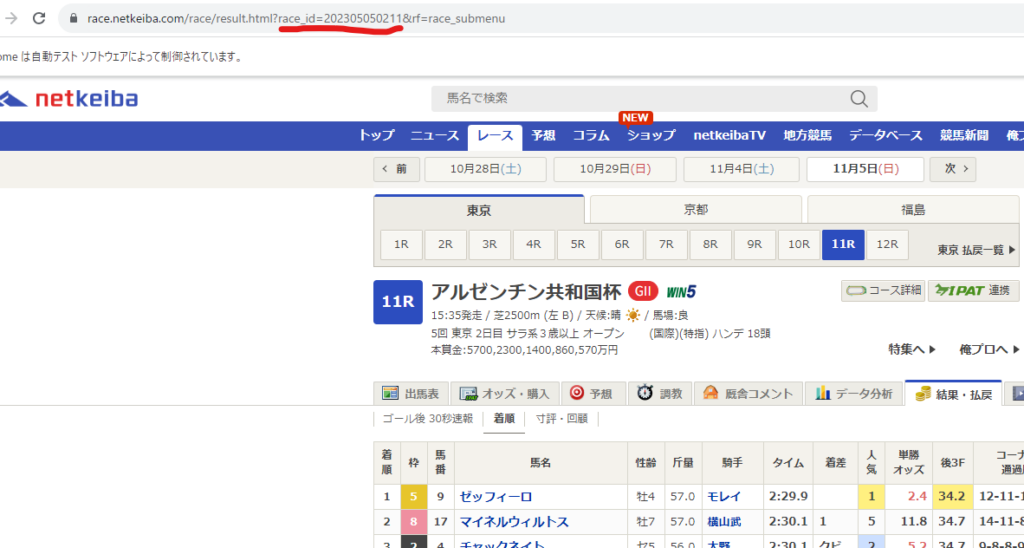
レースIDは前回のレース一覧で取得済みです。(RIDという列名で保存してます)
出走表ページに戻って、欲しい出走表がどのように配置されているか開発者ツールで確認します。
するとテーブルになっているので、こういう時は便利なpandasを使いましょう。
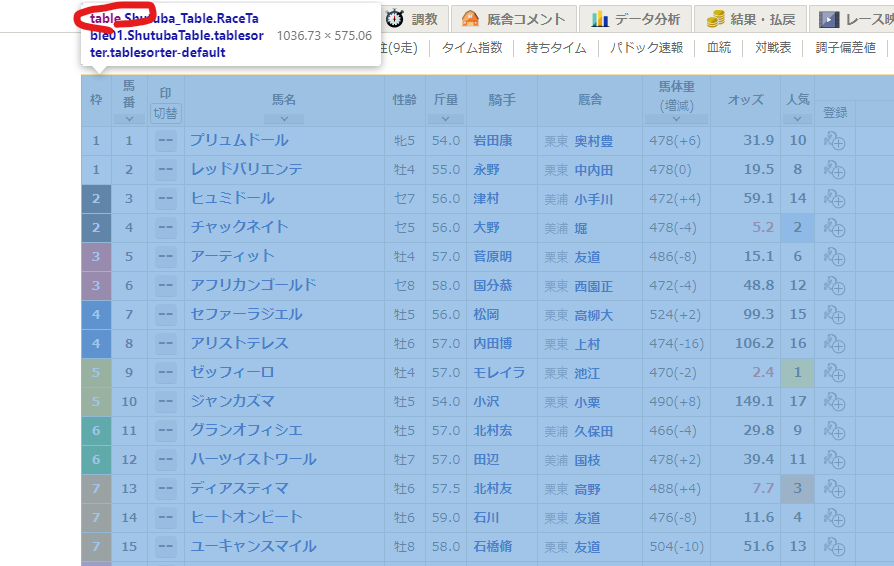
取得テスト
前回同様にget_driver関数でドライバを取得し、出走表のURLを入力してdriver.get(url)します。
そして以下のようにpandasのテーブルタグを読みこんでデータフレームリストで返す関数を使用します
data = pd.read_html(driver.page_source)
len(data) # テーブルが何個読み取られたか
# 5お目当てのデータは最初のリストに格納されていました。
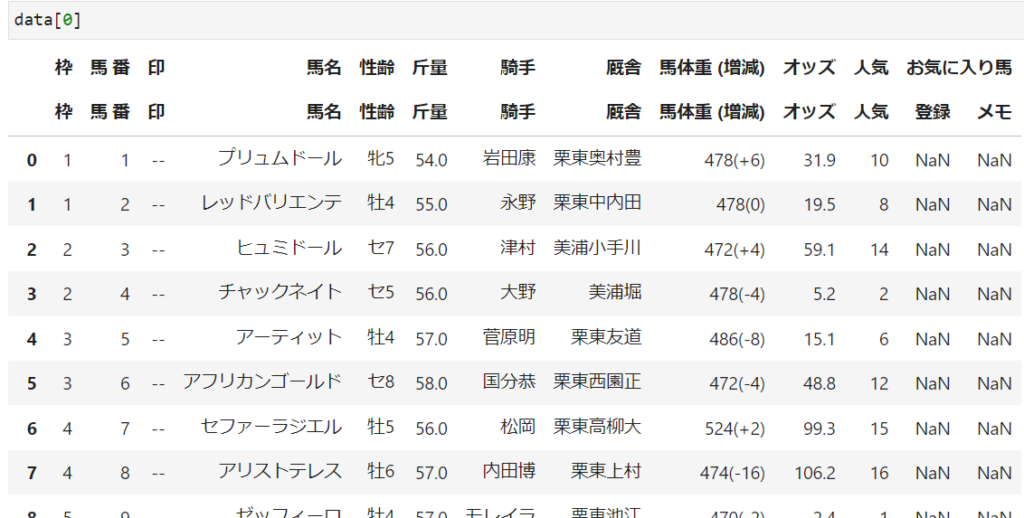
pandasを使用すると簡単に取得できますが、馬名に貼られているリンクは別途取得する必要があります。
今回は省略しますが、作成したツールの方では取得しています。
出走表取得コード
def get_race_table(driver, race_id):
url = f"https://race.netkeiba.com/race/shutuba.html?race_id={race_id}" # 禁止文字列のため、プロトコルやドメインは略
driver.get(url)
sleep(2)
data = pd.read_html(driver.page_source)
race_table = data[0]
return race_table
df = get_race_table(driver, "202305040911") # 天皇賞の秋の出走データを取得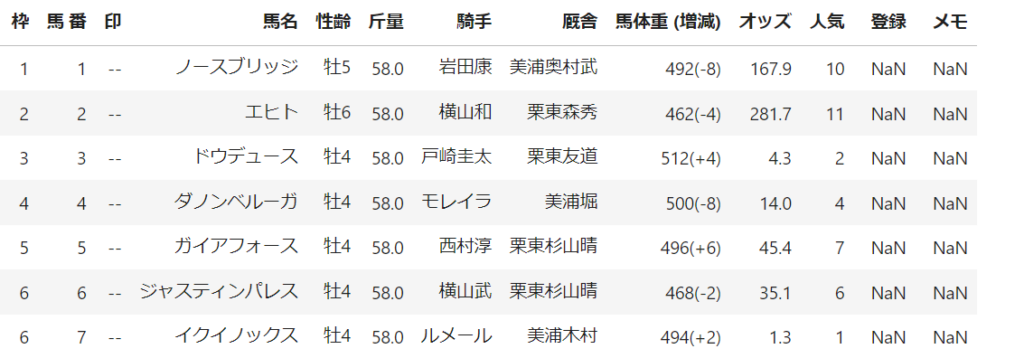
結果と払戻しを取得
続いて結果ページも見てみると、まずURLのshutubaがresultにかわっただけで、結果テーブルと払い戻しはテーブル構造のため、1回のpd.read_html(driver.page_source)でまとめて取得できます。(ついでにラップタイム等も取得できます)
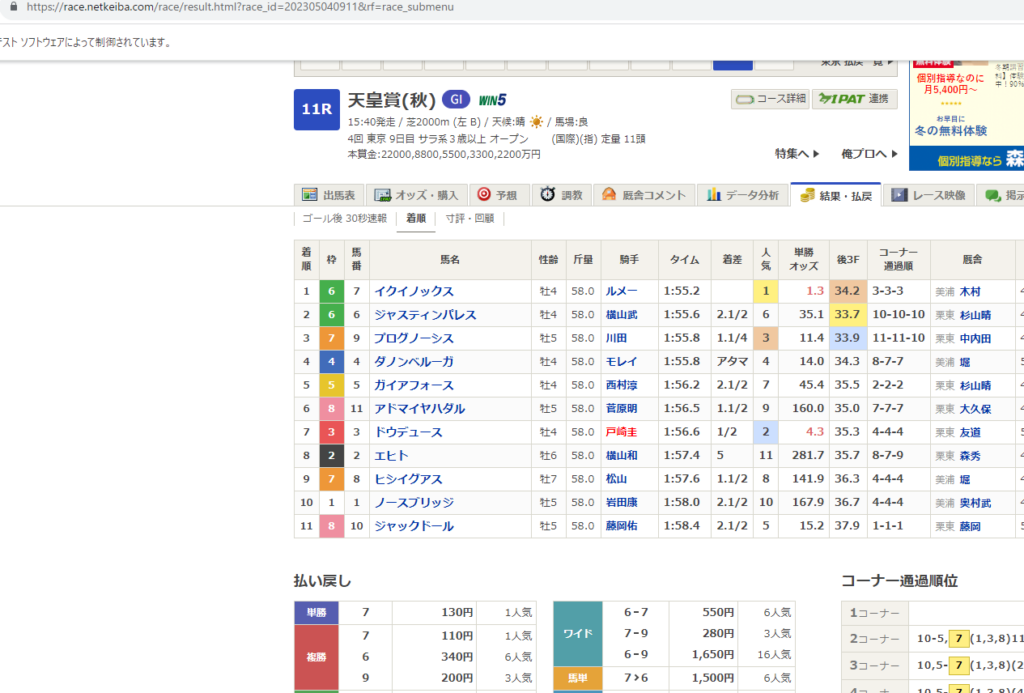
先程の関数を一部いじって少し加工して
def get_race_result(driver, race_id):
url = f"https://race.netkeiba.com/race/result.html?race_id={race_id}" # 禁止文字列のため、プロトコルやドメインは略
driver.get(url)
sleep(2)
data = pd.read_html(driver.page_source)
result_table = data[0] # 結果
payment1 = data[1] # 払い戻し1
payment2 = data[2] # 払い戻し2
return result_table, pd.concat([payment1, payment2])
race_id = "202305040911"
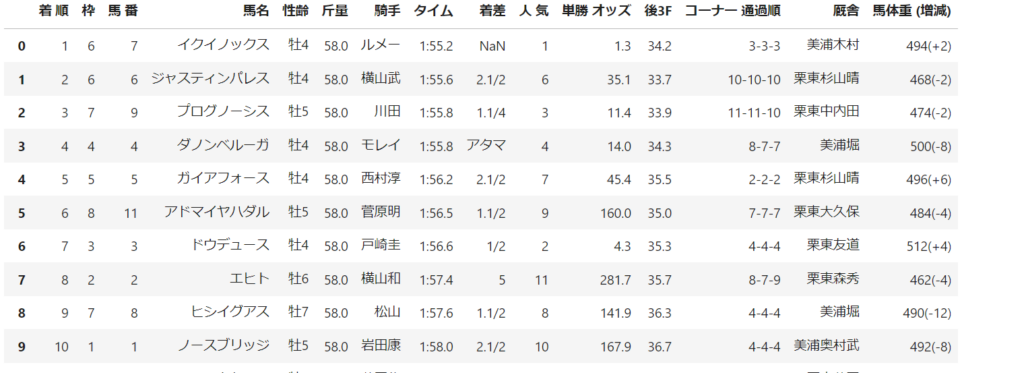
result_table, payment = get_race_result(driver, race_id) # 実行結果
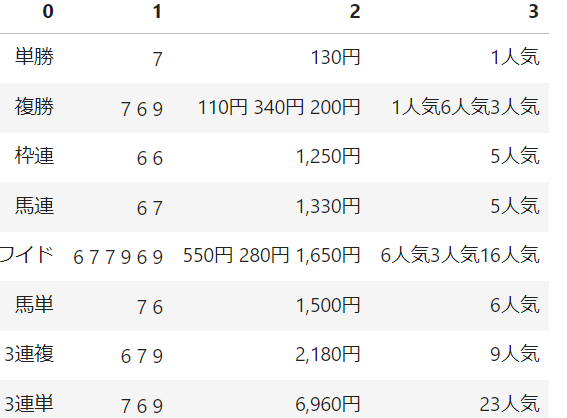
払い戻し
終わりに
以上で出走表と結果の取得は完了です。
あとは前回作成したレースリスト毎にループして出走表と結果を取得できます。
テーブル上のHTMLエレメントはpandasを使うと簡単に取得できますが、リンク等必要な場合は別途タグ解析する必要があります。
作成したツールでは馬コードも取得しております。次回の馬のプロフィールや過去成績データ取得に必要になります。
第2回 競馬の出走表と結果取得ツールを提供します 出走表と結果を自動スクレイピングで取得しよう
